Diving into the Deep
The IDC DataAge Whitepaper assesses where data is being generated, where it is being stored, byte shipments by media type, and a wealth of other information. The following chart from the whitepaper serves to illustrate how data is flowing towards, and reaches the highest concentrations at the core.
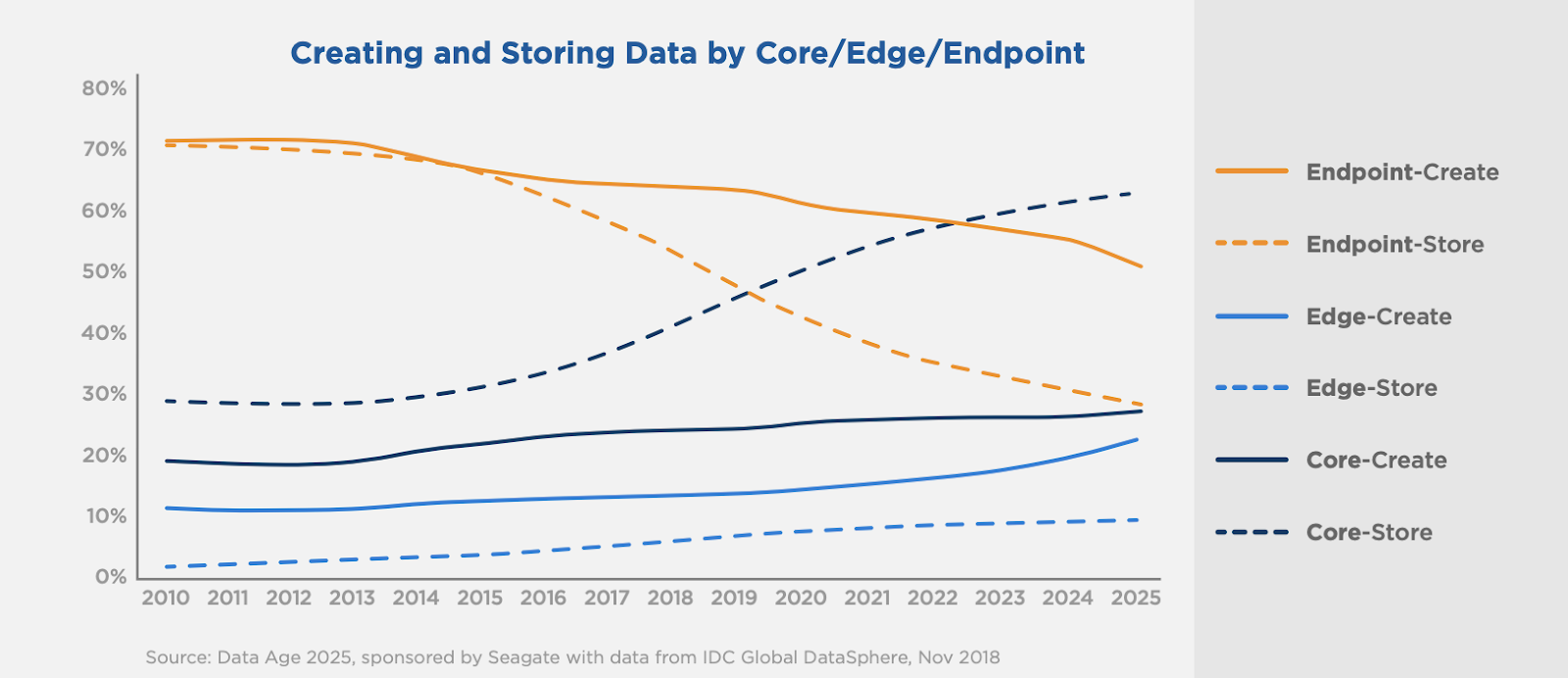
Where there is data, there will be compute power to extract insights. Given the high data concentration at the core, it is perhaps unsurprising to see the highest concentration of general-purpose compute at the core, where large volumes of data are aggregated, filtered, indexed, and cataloged. Decoupling compute and storage is already common at the core, whether it be on-premises, or the public cloud. The trend towards decoupled compute and storage is expected to accelerate with the proliferation of specialized compute hardware like GPUs, FPGAs, and TPUs. In a decoupled data architecture, data is predominately persisted in dedicated object storage systems or services.
In a 2018 interview covering object storage for big data, Mike Olson, former CTO of Cloudera, used “lights out good” to describe the folks working on Ceph. Today, there are organizations and initiatives like Massachusetts Open Cloud leveraging Ceph object storage at the core, serving as both a data lake and as part of a decoupled data warehouse.
Decoupled data warehouses often amount to not much more than a tidier area of a data lake, and the lakehouse moniker is sometimes used to distinguish from the schema on write data warehouse from the days of yore. Beyond analytics, we’re beginning to see a pattern where organizations create a home for even more refined data, where the scalars and vectors that represent features for machine learning are stored; the offline feature store. Interesting features are extracted and/or computed from real time systems, data lakes, and data warehouses, and subsequently loaded into offline feature stores in formats like Uber’s Petastorm, or Tensorflow’s TFRecord.
The feature store pattern decouples feature extraction from consumption. Persisting computed features preserves the exact inputs that were used to train a particular model, and further, become a data product that can be consumed to develop other models. It’s worth noting that even if features are computed from data in a data lake or warehouse, having a purpose built solution for offline feature storage can be advantageous insofar as helping to ensure load from training and batch inference does not interfere with data processing and analytical workloads.
Penguin Computing, Seagate, and Red Hat recently partnered to develop Penguin Computing DeepData with Red Hat Ceph Storage. In the pursuit of this solution, we explored a variety of techniques to maximize the throughput, cost-efficiency and scalability of Ceph object storage as an offline feature store. The results of our testing demonstrate that Ceph object storage is very well suited for deep learning tasks such as direct training, batch inference, or rapidly materializing large amounts of feature data into low latency key-value stores for real time inference.
High Throughput ¶
The key to achieving a high level of throughput with most storage systems is to ensure the data request size is large enough to amortize the overhead of the request. It is increasingly common to see organizations engineering feature extraction pipelines that aggregate features into streaming or columnar datasets, spread across objects measured in megabytes. The tutorial for TFrecord details sharding data across multiple data files, no smaller than 10 MiB, and ideally 100MiB or larger. A great example of streaming dataset usage is captured in this tool which transforms the ImageNet dataset into TFRecord, in preparation for training and validating models like ResNet or MaskRCNN. The throughput required for direct training and batch inference is a function of the number of GPU cores expected to operate on splits of feature data concurrently. The larger the training or inference cluster, the higher the throughput requirement of the storage system.
Cost-Effective ¶
What makes a storage system cost-effective? Low cost per usable unit of storage, and low cost per unit of performance, or in our case, throughput. Capacity needs are dictated by feature volume. The ratio of required throughput to storage capacity is a useful metric in determining the appropriateness and cost-efficacy of a particular storage medium. The Google white paper Disks for Datacenters presents the concept of convex hull to aid in media selection. In the Google paper, the $/GB (y) vs IOPS/GB (x) of the storage device is graphed and the authors propose that the optimal data center storage mix for a certain IOPS/GB target is formed by the lower convex hull in red as shown in this conceptual diagram by the paper’s authors.
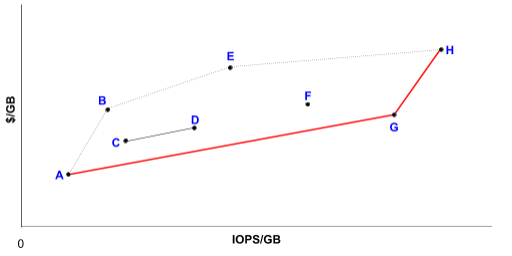
Figure 2. Optimal storage mix for given IOPS/GB is shown in red (source: Disks for Data Centers, Google, 2016)
Spinning disks are currently lower on the y-axis ($:GB) relative to solid state alternatives. Since the publication of the paper, there is no evidence that the growth rate of SSD capacities (with sufficient program-erase cycles) has overcome the growth rate of HDD capacities. Another necessary consideration for media selection is endurance. Stores that expire and ingest new data many times over their projected lifetime will require higher endurance media types. Endurance and cost advantages led us to develop a solution using spinning disk for object data.
Scale ¶
Until recently, we’ve seen mostly large and more advanced organizations examining storage systems specifically for offline feature storage. By examining the volume of feature data they currently struggle with, we can project their future needs and the needs of organizations following in their footsteps.
As an illustrative example, let us consider the volume of feature data being put to use by Tesla’s Dojo supercomputer. Public information is sparse, but at Tesla Autonomy Day (April 2019,) we did get a glimpse into the volume of feature data used for the training and validation of models used for autonomous vehicles. Stuart Bowers disclosed that two years ago they had captured more than 70 million miles (112 million kilometers) of feature data. This feature data was used to develop a series of models that enable Tesla vehicles running in autonomous mode to make lane changes on the highway. As their feature volume grew through their controlled deployment program, they were able to develop better models that resulted in more assertive lane changes.
In the US, advertised miles per gallon (MPG) statistics are informed by testing new vehicles on a dynamo. Vehicles run at an average speed of 48 miles per hour when capturing data for the highway MPG statistic. If we divide the 70 million miles by 48 we arrive at a ballpark 1.5 million hours of feature data extracted from raw data generated by 8 cameras, 12 sonars, 1 radar, gps, and pedal/steering wheel angle sensors. That’s a lot of raw data, and the number of features you could extract from it could potentially eclipse the raw data capacity requirements if all feature data is retained for model explainability, drift detection, and to inform future model development.
In Google’s GPT-3 paper, we learned that nearly 500 billion features (n-gram tokens) were used to train all 8 of the GPT-3 model variants. In Facebook’s SEER paper, we learned that models were trained off of 2 billion images. If you consider the complexity / capacity of the SEER model, the amount of feature data it could extract about the vector-space representing the world an autonomous vehicle is navigating is truly exceptional.
The Solution ¶
As the stacked area chart in Figure 2 illustrates, we were able to achieve a staggering 79.6 GiB/s aggregate throughput from the 10 node Ceph cluster utilized for our testing. Each layer in the stack represents the throughput from each of the 8 client machines randomly reading whole objects from a synthetic data set composed of 350 million objects.
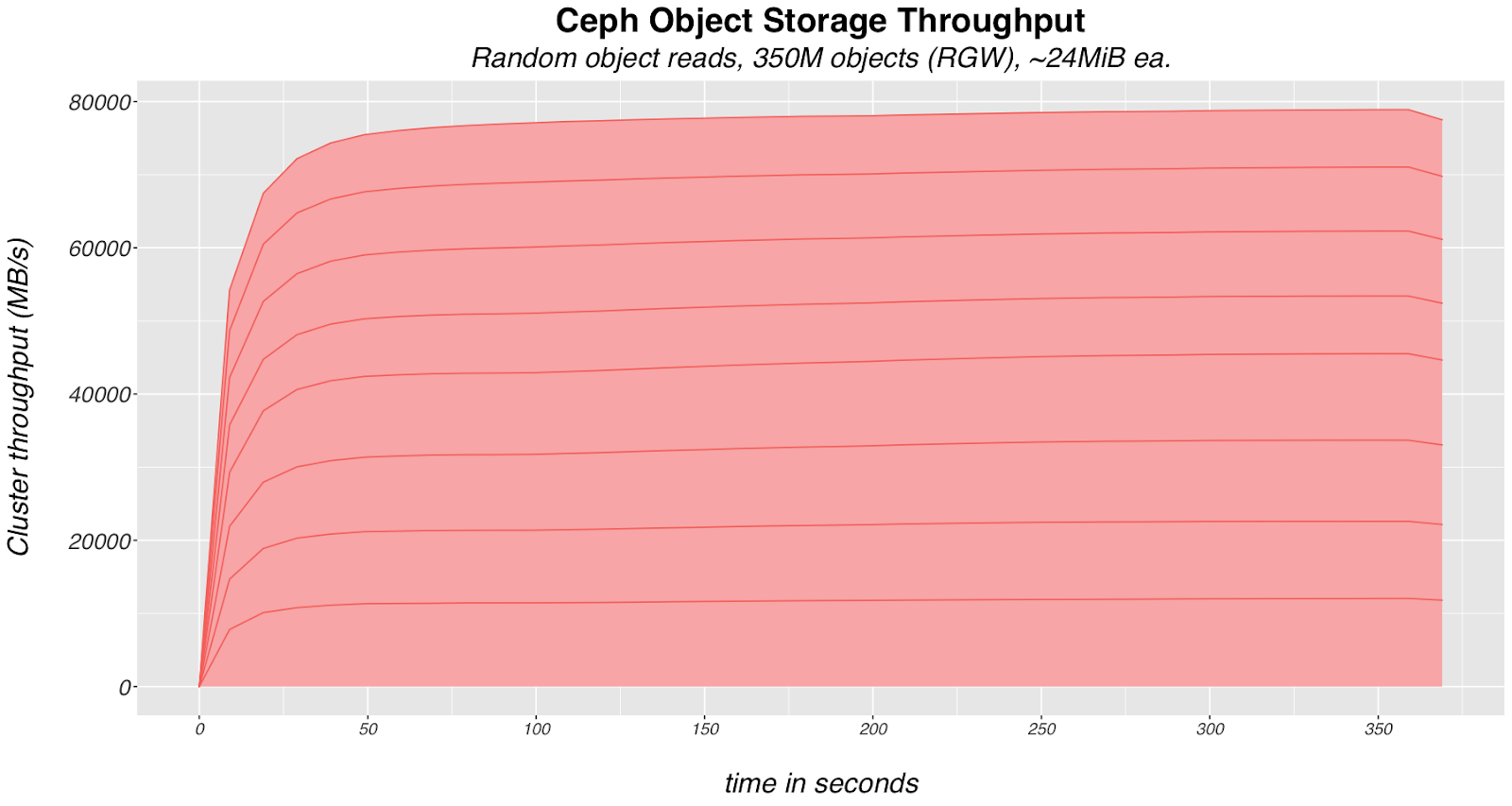
Figure 2. Ceph object throughput for random object read operations using 24MiB objects.
The storage nodes utilized TLC SSDs for metadata (block allocations, checksums, bucket indexes) and were directly attached to 1:1 with Seagate Exos E storage enclosures containing 84 high capacity enterprise disk drives for object data (Seagate Exos X16 16TB SAS). We combined these drives with Ceph’s space efficient erasure coding to maximize cost efficiency. Extracting every bit of usable capacity is especially important at scale, and in support of that objective, we started our optimization effort with the assumption that a cluster should be performant even when approaching 90% disk utilization. A glimpse into our cluster utilization figures before throughput testing commenced:
| RAW STORAGE: CLASS SIZE AVAIL USED RAW USED %RAW USED hdd 12 PiB 1.5 PiB 11 PiB 11 PiB 87.49 TOTAL 12 PiB 1.5 PiB 11 PiB 11 PiB 87.49 POOLS: POOL ID STORED OBJECTS USED %USED MAX AVAIL default.rgw.buckets.data 45 7.8 PiB 350.00M 10 PiB 92.79 623 TiB |
Offline feature storage can push many storage systems to their limits, and to make sure it’s up for the task, we’ve been pushing Ceph’s limits. In February of 2020, we loaded up a 7 node Ceph cluster with 1 billion objects, and by September, we had scaled our test efforts to store 10 billion objects in a 6 node Ceph cluster. Ceph uses algorithmic placement, so the number of objects the cluster is able to store is relative to the number of nodes. By scaling to hundreds of nodes, and using formats like Parquet and TFRecord, Ceph is capable of protecting and providing high-throughput access to trillions of features.
What’s Next ¶
We want to share our experience, and how we tuned Ceph for offline feature storage. We fine-tuned the radosgw, rados erasure coding, and bluestore to work together towards our goals. Not everything we did was intuitive, and simply providing a ceph.conf file without explaining the purpose behind the various parameters we adjusted and how they interact felt like it would be a disservice. Instead we thought it would be beneficial to instead dive into the deep on each of these layers through a series of blog posts (Diving Deeper). Stay tuned!