Diving Deeper
In our first post we introduced the joint development project among Penguin Computing, Seagate, and Red Hat culminating in the Penguin Computing DeepData solution. In this post, we’ll start with first principles, and then discuss some of the hardware and software technical details that drove our configuration changes. In particular, we will demonstrate how to optimize for read throughput with erasure coded data pools.
First Principles ¶
Storage enclosures maximize deployment flexibility, allowing you to adjust the ratio of storage servers to storage enclosures. This results in the ability to fine tune the amount of CPU, memory, and networking available per disk drive. For our testing, we selected the largest Seagate storage enclosure that is able to fit in a standard depth rack - the Seagate Exos 5U84. Each enclosure was loaded with 84 Seagate Exos X16 16TB SAS drives, and paired with a single Altus XE2214GT rack server from Penguin Computing.
Striking an effective balance between throughput and cost can be challenging. We knew that we wanted to push the storage media as close to their physical limits as possible. If we later identified a need to increase throughput relative to capacity, we could either change the number of hosts per storage enclosure or opt for lower capacity storage devices. To establish performance baselines per device and per system, and to ensure there were no system level bottlenecks in the SAS topography, we benchmarked all 84 drives on a single system concurrently using 100% random read fio workloads with various IO sizes and queue depths. The results are detailed in the table below:
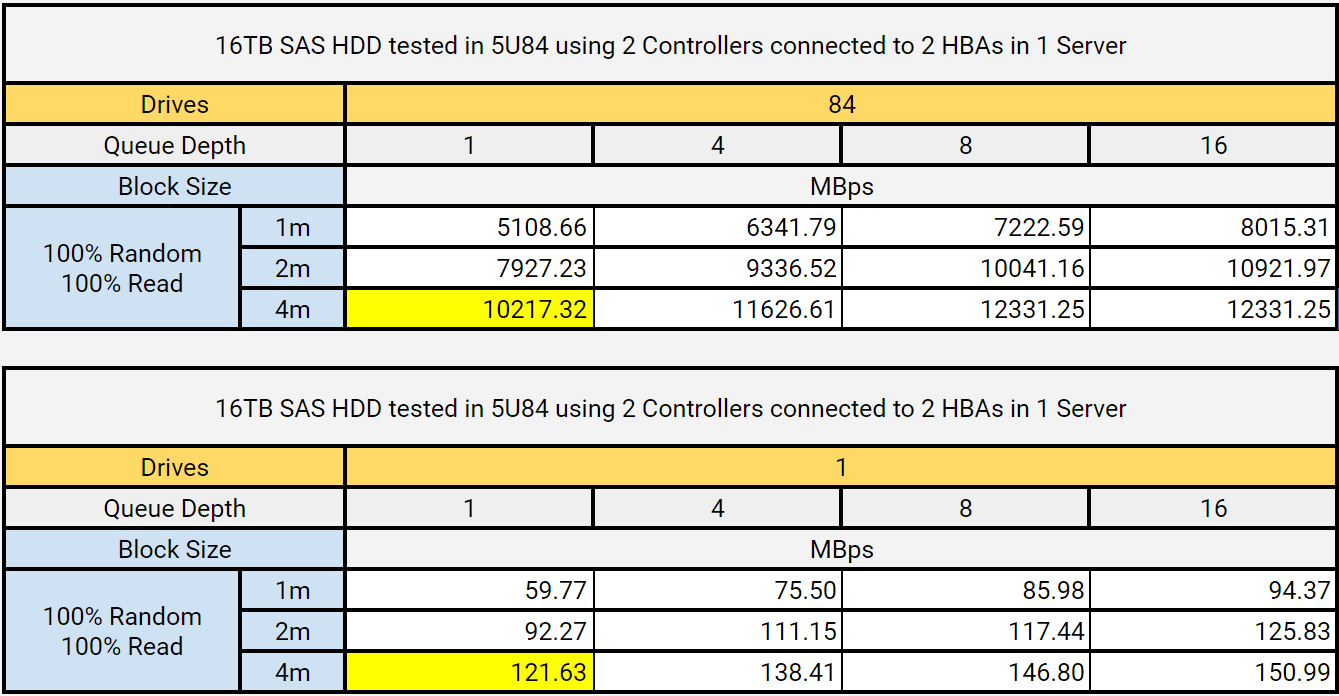
We knew from previous testing that Ceph was capable of achieving per drive performance figures relatively close to these low level results, even with relatively old 4TB drives. Normalizing the performance per drive we previously achieved:
- 75.83 MB/s per OSD with 4+2 EC (erasure coding)
- 88 MB/s per OSD with 3x replication
Granted, this throughput was achieved reading directly from RADOS, and not through the Ceph object gateway (RGW), but we theorized that somewhere in the neighborhood of 100 MB/s might be possible with current generation drives and thoughtful performance tuning.
Erasure Coding ¶
Ceph object storage is deployed quite often with erasure coded data pools, a capability that has been used in mission critical environments for over half a decade. Relative to replication, erasure coding is more cost effective, often consuming half as much disk space. In addition, it can offer enhanced availability and durability by adjusting data and parity chunk quantities and how they are distributed in the cluster.
On read, however, erasure coded pools often generate more disk seeks. We knew that the spread between the EC and replicated figures posted by previous testing could, at least in part, be attributed to this. As an illustrative example, we can look at a the number of disk IOs resulting from single RADOS read operation for a 4 MB object, which is the default object size for RGW, RBD, and CephFS stripes:
- 4MB read from replicated pool = 1x 4MiB IO from 1 HDD
- 4MB read from 4+2 EC pool = 4x 1MiB IO from 4 HDDs
On whole object reads, the number of IOs generated is equal to the number of data chunks (K) used for the erasure code profile of the data pool. This is why using a number of data chunks that is divisible by 4 is advantageous with the default settings — it ensures that data chunks are properly aligned. As an example, data devices for OSDs participating in a 6+3 erasure coded data pool would see operations sized at 682.6 KB with 4MB RADOS objects. It would be much better for the RGW to create 6 or 24MB objects so that the operations hitting the data devices would be sized at 1 or 4MB.
Having analyzed the table of fio results, we expected a big increase in throughput if we could get 4MB IOs all the way down to the disks instead of 1MB IOs. We knew that adjusting our striping configurations could result in 4MB data chunks. The expected result would be similar read throughput to that of a replicated pool with default settings. Write throughput would be higher with an erasure coded pool, since half as many bits would need to be written to disk.
While digging around for clues on how to further optimize for larger IOs, we decided it would be useful to configure the erasure code profile to create a single large EC stripe per RADOS object. We achieved this by setting the stripe_width (stripe_unit * K) equal to the expected RADOS object size. The downside of this sort of configuration is that RADOS objects smaller than stripe_width would be zero padded before encoding. We considered this acceptable for workloads where the application has a high degree of control over the size of objects being persisted in the object store.
In retrospect, adjusting the EC striping may not have been necessary to achieve the level of throughput we observed. That said, we can improve the efficiency of large EC stripes by ushering in functionality like EC efficient sparse objects, and EC partial stripe reads. In future tests, it might also be interesting to experiment with using Bluestore compression to eliminate padding before it is written to disk, perhaps through hinting applied on partial or empty data chunks.
Next Week ¶
It should be evident from the results we previewed in our previous blog post that building upon first principles can prove very effective. The details of this post are intended to help others interested in extracting maximal read performance from erasure coded pools, or even encourage further development and experimentation. In our next post we will go into details of how we configured the Ceph object gateway for maximum read throughput.