Ceph Stretch Clusters Part 3: Handling Failures
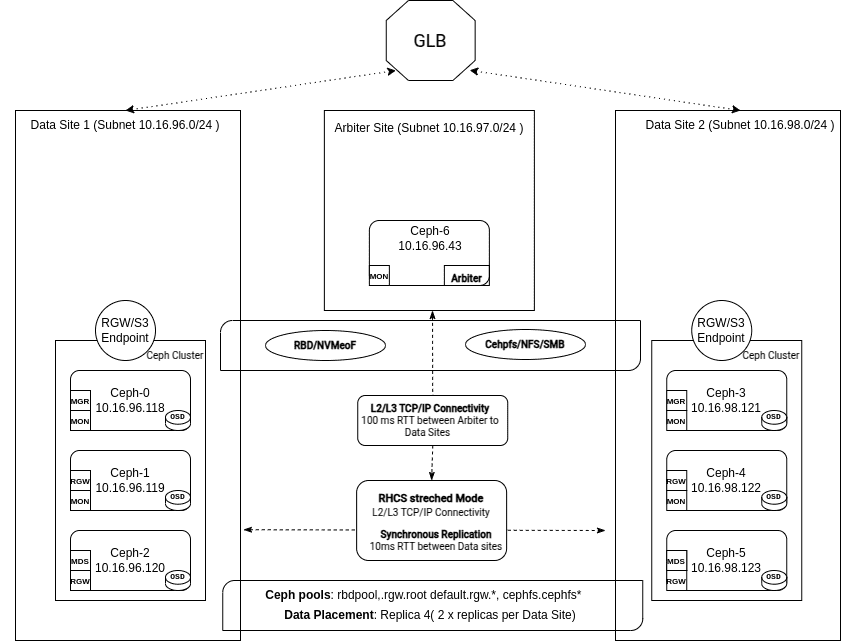
Two-site stretch cluster: Handling Failures ¶
In Part 2 we explored the hands-on deployment of a two-site Ceph cluster with a tie-breaker site and Monitor using a custom service definition file, CRUSH rules, and service placements.
In this final installment, we’ll test that configuration by examining what happens when an entire data center fails.
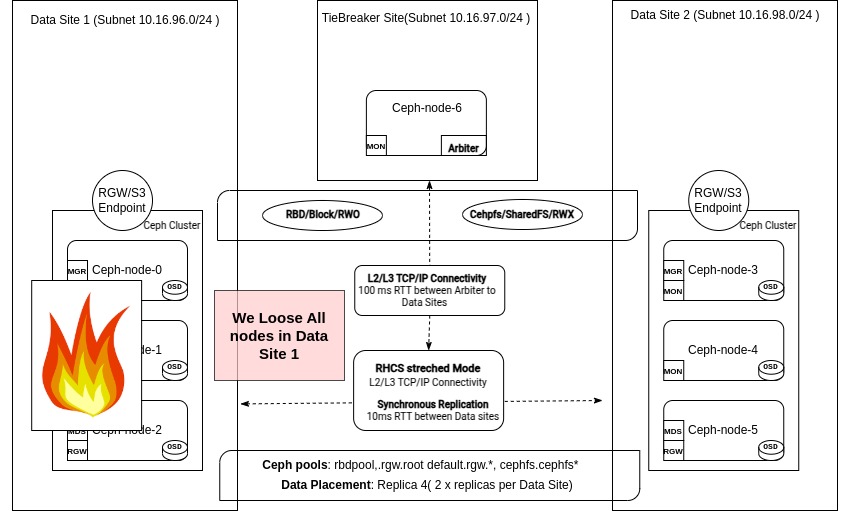
Introduction ¶
A key objective of any two-site stretch cluster design is to ensure that applications remain fully operational even if one data center goes offline. With synchronous replication, the cluster can handle client requests transparently, maintaining a Recovery Point Objective (RPO) of zero and preventing data loss, even during a complete site failure.
Our third and final post in this series will explore how Ceph automatically detects and isolates a failing data center. The cluster transitions into stretch degraded mode, with the tie-breaker Monitor ensuring quorum. During this time, replication constraints are temporarily adjusted to keep services available at the surviving site.
Once the offline data center is restored, we will demonstrate how the cluster seamlessly regains its complete stretch configuration, restoring full redundancy and synchronization operations without manual intervention. End users and storage administrators experience minimal disruption and zero data loss throughout this process.
We Lost an Entire Data Center! ¶
The cluster is working as expected, our monitors are in quorum, and the acting set for our PGs includes four OSDs, two from each site. Our pools are configured with the replication rule, size=4, and min_size 2.
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_OK
services:
mon: 5 daemons, quorum ceph-node-00,ceph-node-06,ceph-node-04,ceph-node-03,ceph-node-01 (age 43h)
mgr: ceph-node-01.osdxwj(active, since 10d), standbys: ceph-node-04.vtmzkz
osd: 12 osds: 12 up (since 10d), 12 in (since 2w)
data:
pools: 2 pools, 33 pgs
objects: 23 objects, 42 MiB
usage: 1.4 GiB used, 599 GiB / 600 GiB avail
pgs: 33 active+clean
# ceph quorum_status --format json-pretty | jq .quorum_names
[
"ceph-node-00",
"ceph-node-06",
"ceph-node-04",
"ceph-node-03",
"ceph-node-01"
]
# ceph pg map 2.1
osdmap e264 pg 2.1 (2.1) -> up [1,3,9,11] acting [1,3,9,11]
# ceph osd pool ls detail | tail -2
pool 2 'rbdpool' replicated size 4 min_size 2 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 199 lfor 199/199/199 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 3.38
We will display a diagram for each phase to describe the various tages during a failure.
At this point, something unexpected happens, and we lose access to all nodes in DC1:
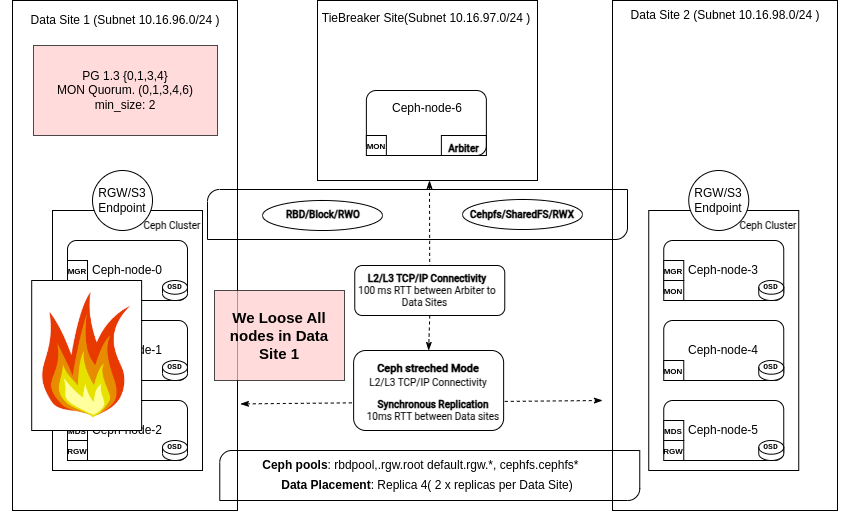
Here is an excerpt from Monitor logs on one of the remaining sites: Monitors in DC1 are considered down and are removed from the quorum:
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : [WRN] MON_DOWN: 2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-00 (rank 0) addr [v2:192.168.122.12:3300/0,v1:192.168.122.12:6789/0] is down (out of quorum)
2025-02-18T14:14:22.206+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : mon.ceph-node-01 (rank 4) addr [v2:192.168.122.179:3300/0,v1:192.168.122.179:6789/0] is down (out of quorum)
The Monitor running on ceph-node-03 in DC2 calls for a monitor election, proposes itself, and is accepted as the new leader:
2025-02-18T14:14:33.087+0000 7f0548201640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 calling monitor election
2025-02-18T14:14:33.087+0000 7f0548201640 1 paxos.3).electionLogic(141) init, last seen epoch 141, mid-election, bumping
2025-02-18T14:14:38.098+0000 7f054aa06640 0 log_channel(cluster) log [INF] : mon.ceph-node-03 is new leader, mons ceph-node-06,ceph-node-04,ceph-node-03 in quorum (ranks 1,2,3)
Each Ceph OSD heartbeats other OSDs at random intervals of less than six seconds. If a peer OSD does not send a heartbeat within a 20-second grace period, the checking OSD considers the peer OSD to be down and reports this to a Monitor, which will then update the cluster map.
By default, two OSDs from different hosts must report to the Monitors that another OSD is down before the Monitors acknowledge the failure. This helps prevent false alarms, flapping, and cascading issues. However, all reporting OSDs may happen to be hosted in a rack with a malfunctioning switch that affects connectivity with other OSDs. To avoid false alarms, we regard the reporting peers as a potential subcluster experiencing issues.
The Monitors OSD reporter subtree level groups the peers into the subcluster based on their common ancestor type in the CRUSH map. By default, two reports from different subtrees are needed to declare an OSD down.
2025-02-18T14:14:29.233+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 prepare_failure osd.0 [v2:192.168.122.12:6804/636515504,v1:192.168.122.12:6805/636515504] from osd.10 is reporting failure:1
2025-02-18T14:14:29.235+0000 7f0548201640 0 log_channel(cluster) log [DBG] : osd.0 reported failed by osd.10
2025-02-18T14:14:31.792+0000 7f0548201640 1 mon.ceph-node-03@3(leader).osd e264 we have enough reporters to mark osd.0 down
2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 2 osds down (OSD_DOWN)
2025-02-18T14:14:31.844+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 host (2 osds) down (OSD_HOST_DOWN)
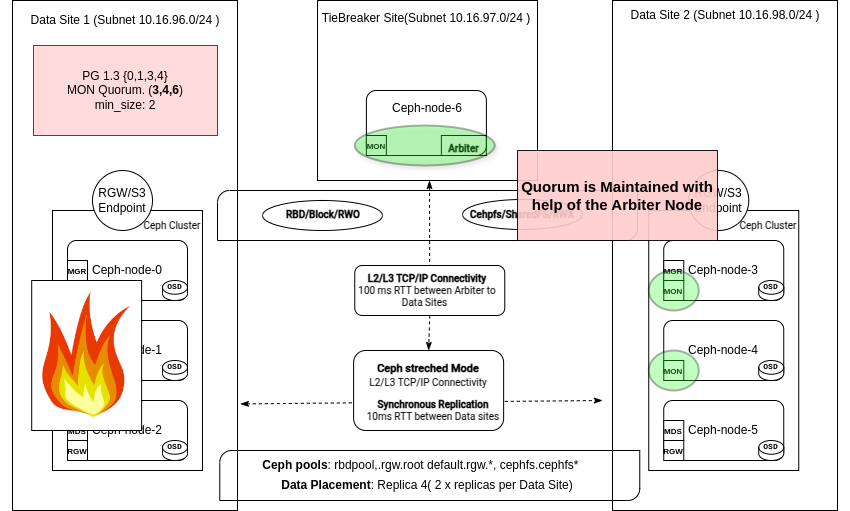
In the output of the ceph status command, we can see that quorum is maintained by ceph-node-06, ceph-node-04, and ceph-node-03:
# ceph -s | grep mon
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
mon: 5 daemons, quorum ceph-node-06,ceph-node-04,ceph-node-03 (age 10s), out of quorum: ceph-node-00, ceph-node-01
We see via the ceph osd tree command that the OSDs in DC1 are marked down:
# ceph osd tree
ID CLASS WEIGHT TYPE NAME STATUS REWEIGHT PRI-AFF
-1 0.58557 root default
-3 0.29279 datacenter DC1
-2 0.09760 host ceph-node-00
0 hdd 0.04880 osd.0 down 1.00000 1.00000
1 hdd 0.04880 osd.1 down 1.00000 1.00000
-4 0.09760 host ceph-node-01
3 hdd 0.04880 osd.3 down 1.00000 1.00000
7 hdd 0.04880 osd.7 down 1.00000 1.00000
-5 0.09760 host ceph-node-02
2 hdd 0.04880 osd.2 down 1.00000 1.00000
5 hdd 0.04880 osd.5 down 1.00000 1.00000
-7 0.29279 datacenter DC2
-6 0.09760 host ceph-node-03
4 hdd 0.04880 osd.4 up 1.00000 1.00000
6 hdd 0.04880 osd.6 up 1.00000 1.00000
-8 0.09760 host ceph-node-04
10 hdd 0.04880 osd.10 up 1.00000 1.00000
11 hdd 0.04880 osd.11 up 1.00000 1.00000
-9 0.09760 host ceph-node-05
8 hdd 0.04880 osd.8 up 1.00000 1.00000
9 hdd 0.04880 osd.9 up 1.00000 1.00000
Ceph raises the OSD_DATACENTER_DOWN health warning when an entire site fails. This indicates that one CRUSH datacenter is unavailable due to a network outage, power loss, or other issue. From the Monitor logs:
2025-02-18T14:14:32.910+0000 7f054aa06640 0 log_channel(cluster) log [WRN] : Health check failed: 1 datacenter (6 osds) down (OSD_DATACENTER_DOWN)
We can see the same from the ceph status command.
# ceph -s
cluster:
id: 90441880-e868-11ef-b468-52540016bbfa
health: HEALTH_WARN
3 hosts fail cephadm check
We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer
2/5 mons down, quorum ceph-node-06,ceph-node-04,ceph-node-03
1 datacenter (6 osds) down
6 osds down
3 hosts (6 osds) down
Degraded data redundancy: 46/92 objects degraded (50.000%), 18 pgs degraded, 33 pgs undersized
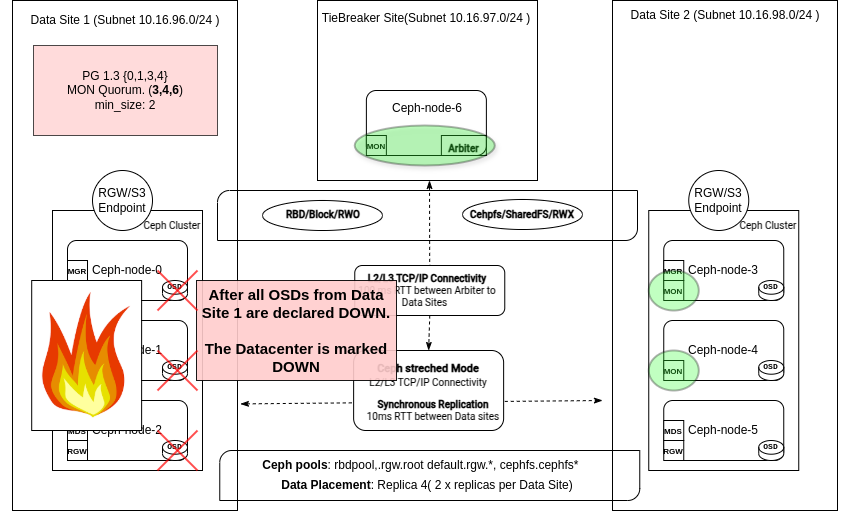
When an entire data center fails in a two-site stretch scenario, Ceph enters stretch degraded mode. You’ll see a Monitor log entry like this:
2025-02-18T14:14:32.992+0000 7f05459fc640 0 log_channel(cluster) log [WRN] : Health check failed: We are missing stretch mode buckets, only requiring 1 of 2 buckets to peer (DEGRADED_STRETCH_MODE)
Stretch Degraded Mode ¶
Stretch degraded mode is self-managing. It kicks in when the monitors confirm that an entire CRUSH datacenter is unreachable. Administrators do not need to promote or demote any site or DC manually. Ceph’s orchestrator updates the OSD map and PG states automatically. Once the cluster enters degraded stretch mode, actions automatically unfold.
Stretch degraded mode means that Ceph no longer requires an acknowledgment from offline OSDs in the failed data center to complete writes or to bring placement groups (PGs) to an active state.
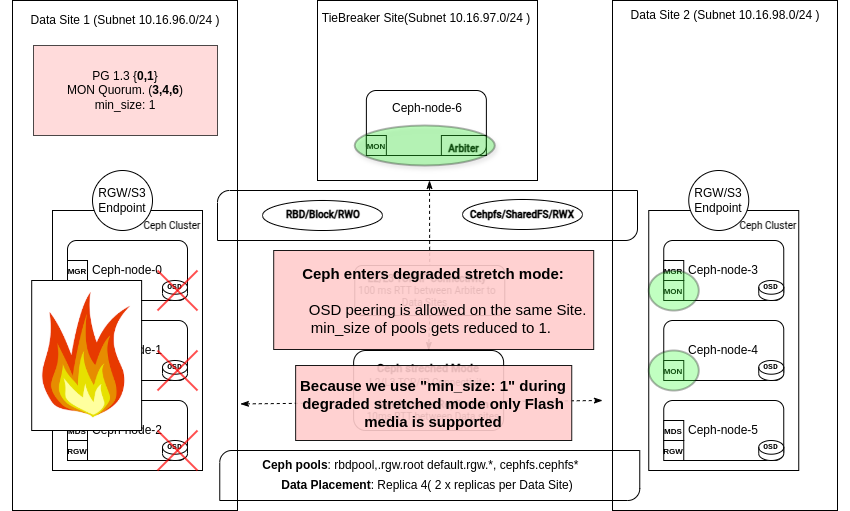
The stretch mode peering rule is relaxed ¶
In stretch mode, Ceph implements a specific stretch peering rule that mandates the participation of at least one OSD from each site in the acting set before a placement group (PG) can transition from peering to active+clean. This rule ensures that new write operations are not acknowledged if one site is completely offline, thereby preventing split-brain scenarios and ensuring consistent site replication.
Once in degraded mode, Ceph temporarily modifies the CRUSH rule so that only the surviving site is needed to activate PGs, allowing client operations to continue seamlessly.
# ceph pg dump pgs_brief | grep 2.11
dumped pgs_brief
2.11 active+undersized+degraded [8,11] 8 [8,11] 8
All pools' min_size is reduced to 1 ¶
When one site goes offline, Ceph automatically lowers the pool’s min_size attribute from 2 to 1, allowing each placement group (PG) to remain active and clean with only one available replica. Were the min_size to remain at 2, the surviving site cannot maintain active PGs after losing half of its local replicas, leading to a freeze in client I/O. By temporarily dropping min_size to 1, Ceph ensures that the cluster can tolerate an OSD failure in the remaining site and continue to serve reads/writes until the offline site returns.
It’s essential to note that running temporarily with min_size=1 means that only one copy of data must be available until the offline site recovers. While this keeps the service operational, it also increases the risk of data loss if the surviving site experiences additional failures. A Ceph cluster with SSD media ensures fast recovery and minimizes the risk of data unavailability or loss when additional component fails during stretch degraded operation.
# ceph osd pool ls detail
pool 1 '.mgr' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 1 pgp_num 1 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool stripe_width 0 pg_num_max 32 pg_num_min 1 application mgr read_balance_score 11.76
pool 2 'rbdpool' replicated size 4 min_size 1 crush_rule 1 object_hash rjenkins pg_num 32 pgp_num 32 autoscale_mode on last_change 302 lfor 302/302/302 flags hashpspool,selfmanaged_snaps stripe_width 0 application rbd read_balance_score 2.62
All PGs for which the primary OSD fails will experience a short blip in client operations until the affected OSDs are declared down and the acting set is modified per stretch mode.
Clients continue reading and writing data from the surviving site's two copies, ensuring service availability and RPO=0 for all writes.
Recovering from stretch degraded mode ¶
When the offline data center returns to service, its OSDs rejoin the cluster, and Ceph automatically moves back from degraded stretch mode to full stretch mode. The process involves recovery and backfill to restore each placement group (PG) to the correct replica count of 4.
When an OSD has valid PG logs (and is only briefly down), Ceph performs incremental recovery by copying only the new updates from other replicas. When OSDs are down for a long time and the PG logs don’t contain the a full set of deltas, Ceph initiates an OSD backfill operation to copy the entire PG. This systematically scans all RADOS objects in the authoritative replicas and updates the returning OSDs with changes that occurred while they were unavailable.
Recovery and backfill entail additional I/O as data is transferred between sites to restore full redundancy. This is why including the recovery throughput in your network calculations and planning is essential. Ceph is designed to throttle these operations via configurable mClock recovery/backfill settings so that it does not overwhelm client I/O. We want to return to HEALTH_OK as soon as possible to ensure data availability and durability, so adequate inter-site bandwidth is crucial. This means not only bandwidth for daily reads and writes, but also for peaks when components fail or the cluster is expanded.
Once all affected PGs have finished recovery or backfill, they return to active+clean with the required two copies up to date and available per site. Ceph then reverts the temporary changes made during degraded mode (e.g. min_size=1 back to the standard min_size=2. The cluster’s degraded stretch mode warning disappears once complete, signaling that full redundancy has been restored.
Quick Demo of a Site Failure and Recovery ¶
In this quick demo we are running an application that is constantly doing reads and writes from an RBD block volume. The blue and green dots are the reads and writes of the application along with latency. On the left and write of the dashboard we have the status of the DCs, and individual servers will be shown as down when they are inaccessible. In the demo we can see how we loose an entire site and our application only reports 27 seconds of delayed IO: the time it takes to detect and confirm that OSDs are down. Once the site is recovered we can see that PGs are recovered using the replicas at the remaining site.
Conclusion ¶
In this final installment, we’ve seen how a two-site stretch cluster reacts to a data center outage. It automatically transitions into a degraded state to keep services online and seamlessly recovers when the failed site recovers. With automatic down marking, relaxed peering rules, lowered min_size values, and synchronization of modified data once connectivity returns, Ceph handles these events with minimal manual intervention and no data loss.
The authors would like to thank IBM for supporting the community with our time to create these posts.