Ceph IO patterns: the bad

Ceph IO patterns analysis part 2: The Bad.
The bad
I.1. Journaling ¶
As soon as an IO goes into an OSD, it gets written twice.
This statement only concerns the Journal.
I.1.1. A single write... ¶
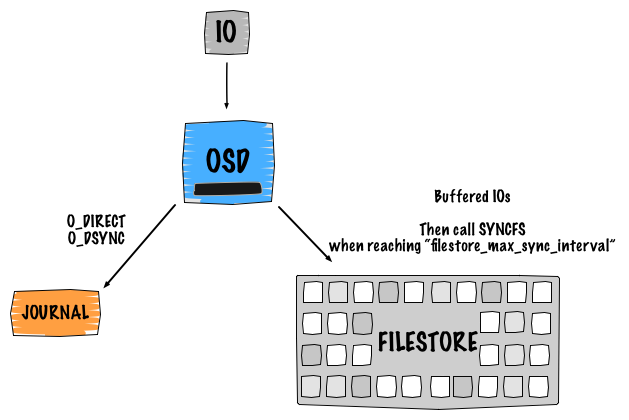
Ceph is Software Defined Storage which means that the replication and the availability of the data are served and ensured by a software intelligence. I believe it is important to understand how Ceph works internally (default logical design). The main point here is to show you what is happening under the hood while performing a write operation. So for this, let's take an example of a single object write with a replica of 2. This leads to 4 IOs:
- Client sends his request to the primary OSD
- The first IO is written to the Ceph journal
- The journal uses libaio and writes with
O_DIRECTandO_DSYNC. The write is processed withwritev() - The second IO is written to the backend filesystem with
buffered_io. The write is processed withwritev() - The filestore calls
syncfsand trim the journal when reachingfilestore_max_sync_intervaland waits forsyncfsto finish before releasing the lock.
The same process is repeated to the secondary OSD for replication.
I.1.2. About the journal ¶
In the previous paragraph, I mentioned a journal but what does it do exactly? Well it does numerous things such as:
- Ensuring data and transaction consistency. It basically acts as a traditional filesystem journal, so it can replay stuff if something goes wrong.
- Provides atomic transactions. It keeps track of what was committed and what is going to be committed.
- Writes to the journal happen sequentially
- Works as a FIFO
Ceph OSD Daemon stops writes and synchronises the journal with the filesystem, allowing Ceph OSD Daemons to trim operations from the journal and reuse the space.
The above statements are not applicable if the OSD filesystem is Btrfs or ZFS. Traditionally, we recommend to use XFS or ext4 for the OSD filesystem, which makes the journal using the mode writeahead. We before write to the journal and then to the backend filesystem. This is a different approach with COW (Copy On Write) filesystems, the writeparallel mode is used. We write to the journal and the backend filesystem at the same time.
I.1.3. Design penalty ¶
Obviously, you already noticed that having a journal performing in writeahead mode causes a huge performance penalty while writing objects. Since we write twice, if the journal is stored on the same disk as the osd data this will result in the following:
Device: wMB/s
sdb1 - journal 50.11
sdb2 - osd_data 40.25
Traditional enterprise SATA disks can deliver around 110 MB/sec for a sequential write IO pattern. So yes, basically we split into two our IOs.
In order to avoid (or hide) this effect there are several ways to implement the journal.
Usually, the Ceph journal is a just a file on the filesystem (under /var/lib/ceph/osd/<osd-id>/journal). First, this is extremely inefficient because of the filesystem overhead and second we don't exactly know where the journal is placed on the hard drive disk (correlation between files and blocks).
Another way to implement it is by using a raw partition at the beginning of the OSD data disk. Basically, you just create a tiny partition using the first sectors. Since we are at the start of the device, we are sure that this is a fastest zone of the disk. The border is always faster and as soon as the arm gets closer to the center of the plater performance starts to decrease (it is a well known problem). It is probably the best way to use the journal if you don't want to dedicate a disk for it.
Then if you want to bring higher performance you can use a separate spinning disk. Unfortunately, this won't perform very well since the disk will spend most of its time seeking to write because of the concurrent journal writes occurring (multiple journal writes).
Finally, the best way to implement the journal is to use a separate SSD disk. Thanks to it, you get the common benefits of using a SSD such as: no seek, fast sequential writes and fast access times.
II. Filesystem fragmentation ¶
Each object stored in Ceph, appears as a file on the backend filesystem. By default, these objects live under /var/lib/ceph/osd/<osd.id>/current/<pg.id>/. Due to its distributed nature as a dynamic cluster, Ceph is always performing writes, updates and objects (understand files here) operations. Such load is quite heavy for traditional filesystems, so intense that this could lead to a large fragmentation. Obviously, the effect will be seen overtime, since nowadays, filesystems have mechanisms such as delayed allocation that tend to efficiently control filesystem fragmentation. If you use RBD, the block device functionality for virtual machines and bare metal machines, object chunks have a 4MB size (default stripe). However, every single image that lives in a Ceph cluster can have its own stripes and way more.
Note: filesystem fragmentation is rarely taken into account as it is quite difficult to simulate aged-filesystem.
On a Ceph environment, we can fairly say that over time performance will tend to decrease. This is for instance what you can get after a one year old cluster:
bash $ sudo xfs_db -c frag -r /dev/sdd actual 196334, ideal 122582, fragmentation factor 37.56%
Fortunately, an ongoing work has been initiated recently by the Ceph core developers. This new functionality is called RADOS IO hints. This will mirro what fadvise(2) does. fadvise(2) is a system call that can be used to give Linux hints about how it should be caching files. So that the kernel can choose appropriate read-ahead and caching techniques for access to the corresponding file. For more details about the implementation, please look at the mailing list discussion.
III. No parallelized reads ¶
Currently, Ceph does not provide any parallel reads functionality, which means that Ceph will always serve the read request from the primary OSD. Since we often have 2 or more copies, general read performance could be drastically improved. I recall a discussion on the Ceph mailing list about this, however I can't find any pointers. However I am sure it's part of the Ceph developers TODO :).
IV. Deep scrub kills your IOs ¶
The scrub is a fsck for objects. It check the objects consistency at the PG level and compares replicas versions against the primary object.
There are two kind of scrub:
- Light scrubbing (daily) checks the object size and attributes.
- Deep scrubbing (weekly) reads the data and uses checksums to ensure data integrity.
A lot of users reported that the deep scrub had a major impact against the cluster. To fight this IO penalty options are quite limited here, you can still disable it but you are on your own and try to control the behavior with proper options.
Ceph wants to keep your transaction and data as safe as possible. This, obviously has a price to pay, performance. However we have seen several techniques to workaround this design penalty. See you next time for the last part: The Ugly.