Ceph cache pool tiering: a scalable and distributed cache

Moving further on the Software Defined Storage principles, Ceph, with its latest stable version introduced a new mechanism called cache pool tiering. It brings a really interesting concept that will help us to provide scalable distributed caching.
No more RAID! That what she said... (+pics?)
I've got asked quite often about software caching layers. Indeed solutions such as Flashcache, bcache or fatcache have become really popular. However the main drawback of these system is that they tend to be quite complex to implement and even worst to maintain in production. More than a year ago I experimented Flashcache in this article. I believe such systems provide performance boost however managing them in production is a real nightmare. They add too much complexity to your setup and I don't think you take a real benefit from them. Moreover
Before we dive into any design architecture example, I'd like to spend some time introducing the cache pool overlay from Ceph. As mentioned already, the cache pool functionality brings a distributed and massively scalable cache. Several modes are currently available:
- Read-write pool, commonly known as writeback: we have an existing data pool and put a fast cache pool "in front" of it. Writes will go to the cache pool and immediately ack. We flush them back to the data pool based on the defined policy.
- Read-only pool, weak consistency: We have an existing data pool and add one or more read-only cache pools. We copy data to the cache pool(s) on read. Writes are forwarded to the original data pool. Stale data is expired from the cache pools based on the defined policy.
As any tiering solution, the cache has several parameters that can be tuned such as cache size (number of objects or size), data retention in the cache, dirty ratios.
Design implementation
Now that you got the big picture, let's talk design! This will nicely fit into your OpenStack environment. From a Cinder perspective, we can imagine a tiering type that points to the cache pool.
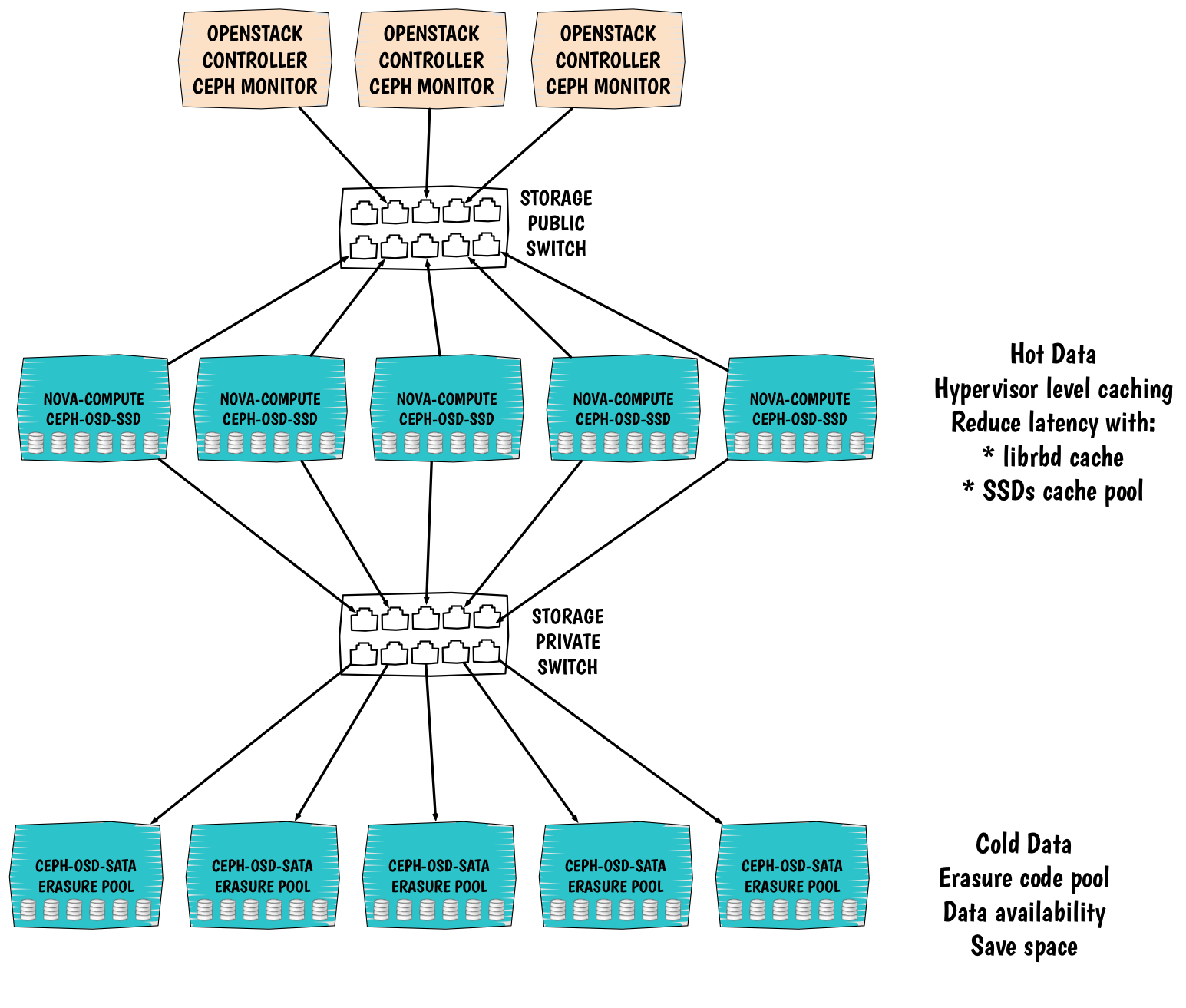
There is one design that I really like, though I still haven't got the chance to experiment it:
This setup is relatively new and relies on the latest version of Ceph: Firefly.
The main purpose of this design to provide:
- Scalability: all the compute and storage nodes horizontally scale. If you need more resource, just add a node and you will also get more space.
- Resilience and data availability: just like a common pool in Ceph both Cache and Erasure object pools are distributed across all the storage servers.
- Fast storage: with an efficient caching mechanism we are able to ensure pretty good performance, by putting SSD on the compute nodes we restrain the IOs at the hypervisor level. In this situation, we can expect a first data local hit. Having a local cache dramatically reduce the latency.
- Cheap density oriented storage: while we have hot data with the cache pool we also have cold data. Hot data are periodically moving out of the cache to the cold data pool. This pool has an erasure type. Thanks to the erasure code we can store all of our data more efficiently and save a lot of space depending on the profile (compression level) that we set to the erasure pool. Obviously here we use big SATA disks.
- Administration ease: with this setup we keep things really simple. Operators will be more than happy :).
I hope you enjoyed this walk through into a new amazing Ceph feature. Until next time :).